Tagebuch-Eintrag #45
Webseite Crawlen mit Python
Vor gut einer Woche habe ich das Thema Webseiten crawlen abarbeitet und weiß nun, was ich benötige um Informationen aus Webseite auszulesen.
Als ich vorher darüber gelesen hatte, kam mir schon den einen oder anderen praktischen Nutzen in den Sinn. Zum Beispiel verschiedene HTML-Tabellen auslesen und nur die Informationen in den Zellen weiterverarbeiten, die man braucht.
Aber das ist dann was für später. Also, was habe ich gelernt und was brauche ich um Webseiten zu crawlen?
Module
Zunächst einmal, muss ich dafür verschiene Module importieren
import requests
from bs4 import BeautifulSoupRequest ist dafür da um eine Anfrage zu einer Webseite zu schicken. Diese Webseite wird dann wiederrum im BeautifulSoup ausgelesen und der HTML-Code der Webseite wird dargestellt.
Als Beispiel crawle ich meine eigene Python-Tagebuch-Seite:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import time
url = "https://python-tagebuch.de"
source = requests.get(url)
soup = BeautifulSoup(source.text, "html.parser")
for post in soup.select("article"):
title = post.select_one(".h2-title")
excerpt = post.select_one(".mypy-the_excerpt")
content = post.select_one(".mypy-the_content")
print(title)
print(excerpt)
print(content)
print("-----" * 5)In der for-Schleife, gebe ich dann alle Überschriften, Auszüge (Excerpt) und Inhalte aus.
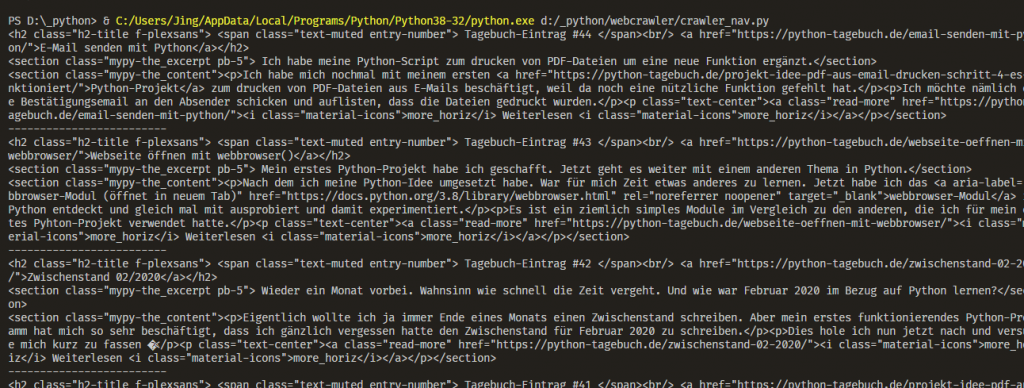
Im ersten Moment klappt das schon. Sieht aber nicht brauchbar aus wegen den ganzen HTML-Code drumrum. Um diesen zu „entfernen“, gibt die Methode .text von BeautifulSoup. Diese Methode hänge ich bei meinen Überschriften, Auszüge und Inhalt in der for-Schleife mit dran. Dann sieht der Code so aus:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import time
url = "https://python-tagebuch.de"
source = requests.get(url)
soup = BeautifulSoup(source.text, "html.parser")
for post in soup.select("article"):
title = post.select_one(".h2-title").text
excerpt = post.select_one(".mypy-the_excerpt").text
content = post.select_one(".mypy-the_content").text
print(title)
print(excerpt)
print(content)
print("-----" * 5)Und die dazugehörige Ausgabe im Terminal von VS Code:
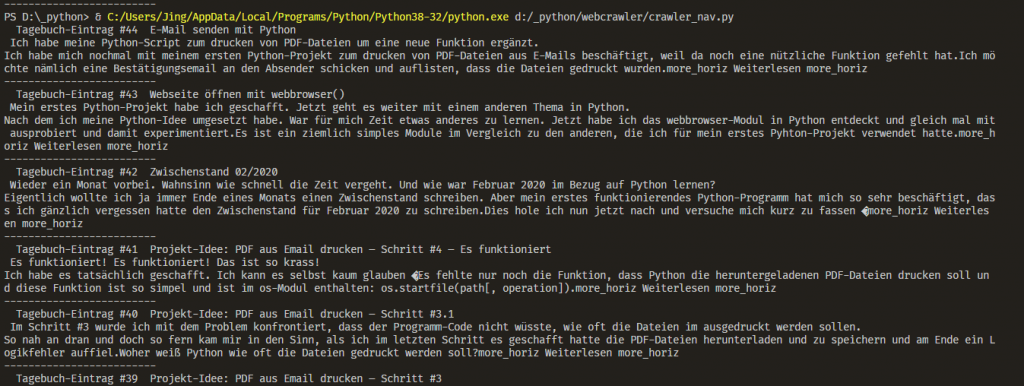
Also, es funktioniert ziemlich gut. Ich kann dann allerhand Sachen damit machen. Es in einer Liste speichern und/oder in einer CSV-Datei und und und.